Frameworks and Sample Graphs
The shared task combines five frameworks for graph-based meaning representation, each with its specific formal and linguistic assumptions. Definitions of basic graph theoretic terminology and of relevant formal properties are available as a separate page. Following are some example graphs for sentence #20209013 from the venerable Wall Street Journal Corpus (WSJ):
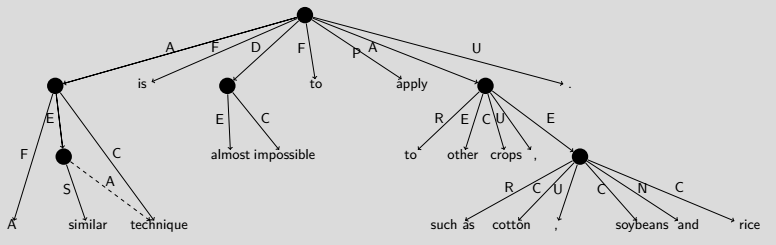
A similar technique is almost impossible to apply to other crops, such as cotton, soybeans and rice.
The example exhibits some interesting linguistic complexity, including a so-called tough adjective (impossible), an arguably scopal adverb (almost), a tripartite coordinate structure, and apposition. The example graphs below are presented in order of (arguably) increasing ‘abstraction’ from the surface string, i.e. ranging from ordered Flavor (0) semantic graphs to unanchored Flavor (2) graphs.
DM: DELPH-IN MRS Bi-Lexical Dependencies
PSD: Prague Semantic Dependencies
Two of the frameworks in the shared task present simplifications into bi-lexical semantic dependencies (i.e. lossy reductions) of independently developed syntactico-semantic annotations. These representations were first prepared for the Semantic Dependency Parsing (SDP) tasks at the 2014 and 2015 Semantic Evaluation Exercises (SemEval). The SDP graph banks (LDC2016T10) comprise multiple linguistic frameworks, but we focus on (a) DELPH-IN MRS Bi-Lexical Dependencies (DM; Ivanova et al., 2012) and (b) Prague Semantic Dependencies (PSD; Hajič et al., 2012; Miyao et al., 2014). Both are rooted in general theories of grammar—Head-Driven Phrase Structure Grammar (Pollard & Sag, 1994) and Prague Functional Generative Description (FGD; Sgall et al., 1986), respectively—where the simplifications into DM and PSD essentially recast core predicate–argument structure in the form of pure bi-lexical dependency graphs. Thus, these representations instantiate Flavor (0) in our hierarchy of different formal types of semantic graphs.
Although graph nodes in DM and PSD correspond to surface tokens, these graphs are neither fully connected nor rooted trees, i.e. some tokens from the underlying sentence remain structurally isolated, and for some nodes there are multiple incoming edges. In the example DM graph below, technique is semantically dependent on the determiner (the quantificational locus), the modifier similar, and the predicate apply. Conversely, the predicative copula, infinitival to, and the vacuous preposition marking the deep object of apply can be argued to not have a semantic contribution of their own. In the DM and PSD examples below, nodes colored in red indicate the top of the graph.
Similarly, the PSD graph for our running example has many of the same dependency edges (albeit using a different labeling scheme and inverse directionality in a few cases), but it analyzes the predicative copula as semantically contentful and does not treat almost as ‘scoping’ over the entire graph. Also, the PSD graph has recursively propagated argument dependencies to both elements of the apposition and to all members of the coordinate structure.
EDS: Elementary Dependency Structures
The DM bi-lexical dependencies originally derive from the underspecified logical forms computed by the English Resource Grammar (Flickinger et al., 2017, Copestake et al., 2005), which Flickinger et al. (2015) dub English Resource Semantics (ERS). Elementary Dependency Structures (EDS; Oepen & Lønning, 2016) encode English Resource Semantics in a variable-free semantic dependency graph, where graph nodes correspond to logical predications and edges to labeled argument positions. The EDS conversion from underspecified logical forms to variable-free graphs discards the partial information on semantic scope from the full ERS, which makes these graphs abstractly—if not linguistically—quite similar to Abstract Meaning Representation (see below).
Nodes in EDS are in principle independent of surface lexical units, but for each node there is an explicit, many-to-many anchoring onto sub-strings of the underlying sentence. Thus, EDS instantiates Flavor (1) in our hierarchy of different formal types of semantic graphs. In the EDS analysis for the running example, nodes representing covert quantifiers (on bare nominals, labeled udef_q), the two-place such+as_p relation, as well as the imp(licit)_conj(unction) relation (which reflects recursive decomposition of the coordinate structure into binary predications) do not correspond to individual surface tokens (but are anchored on larger spans, overlapping with anchors from other nodes).
UCCA: Universal Conceptual Cognitive Annotation
A second instance of Flavor (1) semantic graphs in the shared task is presented by the Universal Conceptual Cognitive Annotation framework (UCCA; Abend & Rappoport, 2013). UCCA is a comparatively recent initiative, which targets a level of semantic granularity that abstracts away from syntactic paraphrases in a typologically-motivated, cross-linguistic fashion—without relying on language-specific resources—while setting a low threshold for annotator training. UCCA has been the subject of a recently completed parsing task at SemEval 2019. The UCCA parser by Hershcovich et al. (2018) is one of the few instances of multi-task learning across meaning representation frameworks to date.
A UCCA analysis of a text passage is a directed acyclic graph over semantic elements called units, which are the nodes of the graph. A unit corresponds to (is anchored by) one or more tokens and can be related to its parent unit with one or more semantic categories (i.e. edges). The basic unit of annotation is the scene, denoting a situation mentioned in the sentence, typically involving a predicate, participants, and potentially modifiers. Linguistically, UCCA adopts a notion of semantic constituency that transcends pure dependency graphs, in the sense of introducing separate, unlabeled nodes (the units). The shared task limits itself to UCCA annotations at what is called the foundational layer, where there is a comparatively coarse inventory of different relations.
The UCCA graph for the running example (see below) includes a single scene, whose main relation is the Process (P) evoked by apply. It also contains a secondary relation labeled Adverbial (D), almost impossible, which is broken down into its Center (C) and Elaborator (E); as well as two complex arguments, labeled as Participants (A). Unlike the other frameworks in the task, UCCA integrates all surface tokens into the graph, as the targets of semantically bleached Function (F), and Punctuation (U) edges. UCCA graphs need not be rooted trees: argument sharing across units will give rise to reentrant nodes much like in the other frameworks. For example, technique is both a (remote) Participant in the scene evoked by similar and a Center in the parent unit. UCCA in principle also supports implicit (unexpressed) units which do not correspond to any tokens, but these are currently excluded from parsing evaluation and, thus, suppressed in the UCCA graphs distributed in the context of the shared task.
AMR: Abstract Meaning Representation
Finally, the task includes Abstract Meaning Representation (AMR; Banarescu et al., 2013), which in our hierarchy of different formal types of semantic graphs is simply unanchored, i.e. represents what we call Flavor (2). The AMR framework backgrounds notions of compositionality and derivation and, accordingly, declines to make explicit how elements of the graph correspond to the surface utterance. Although most AMR parsing research presupposes a pre-processing step that aligns graph nodes with (possibly discontinuous) sets of tokens in the underlying input, these correspondences are not part of the meaning representation proper. At the same time, AMR frequently invokes lexical decomposition and normalization towards verbal senses, such that AMR graphs quite generally appear to ‘abstract’ furthest from the surface signal. Since the first general release of an AMR graph bank in 2014, the framework has provided a popular target for data-driven meaning representation parsing and has been the subject of two consecutive tasks at SemEval 2016 and 2017.
The AMR example graph below has a topology broadly comparable to EDS, with notable differences. The nodes corresponding to similar and such as, for example, in AMR are analyzed as derived from the resemble-01 and exemplify-01 verbal senses. Furthermore, the AMR representation of the coordinate structure is flat, the directionality of :mod(ifier) edges reversed in comparison to EDS, and there is no meaning contribution annotated for the determiner a (let alone for covert determiners in bare nominals).